
Artificial Intelligence 101: A Guide for Product Managers


What if the single biggest skill gap separating good product managers from great ones in 2026 isn’t roadmapping, prioritisation, or stakeholder management but simply knowing how to think with (and about) AI?
Not in a technical, intimidating way; but in a practical, grounded way that helps you understand what AI actually is, its various components and what it changes about how we build products.
Over the past 2–3 years, AI has moved from being an “interesting trend” to becoming a core capability shaping sectors, products, strategy, user experience, and even how teams operate internally.
If you’re one of the many people still trying to make sense of AI, caught between buzzwords, vendor demos, and overly technical explanations, The Product Notebook is here to help.
Throughout this month, we’ll be exploring AI from a product manager’s perspective: breaking down concepts, clarifying terminology, and connecting theory to real-world product thinking. But today, we’re starting from the foundations.
Think of this as a practical starting point and a way to understand the fundamentals without getting lost in the complexities.
In this edition, we’ll focus on the foundational parts that are important for Product Managers to understand:
How AI works at a high level and why it behaves differently from traditional software
The Different Ways AI Learns
The Core building blocks for AI
Popular types of AI
Common types of AI models and
Key AI terminologies worth knowing
P.s - It’s a bit of a long read but its definitely worth it!
Ready? Let’s go.
What is Artificial intelligence?

Artificial Intelligence (AI) refers to a class of computer systems designed to perform tasks that would normally require human judgment or intelligence; things like recognising patterns, understanding language, learning from experience, and making decisions.
Now, what makes AI different from traditional software isn’t what it does, but how it does it.
Traditional software operates on explicit instructions:
“If this happens, do that.”
Every possible outcome has to be anticipated and coded in advance.
AI systems, on the other hand, don’t rely on fixed rules. They learn from data. By observing examples, they identify patterns and use those patterns to make predictions or decisions:
“Given the patterns I’ve learned from past data, this is the outcome that’s most likely.”
So, Instead of being told exactly what to do in every situation, AI systems infer what to do based on learning/training experience.
The Different Ways AI Learns

Now that we understand that AI systems learn from data rather than follow fixed rules, the next important question becomes:
How does that learning actually happen?
The answer? Machine Learning.
Machine learning is the practice of training systems to learn from data instead of following explicitly programmed rules in order to identify patterns, make predictions, and improve their performance over time.
Within machine learning, there are different levels of complexity in how systems learn from data.
Some approaches rely more on human guidance to define what patterns to focus on, while others allow the system to automatically discover patterns through exposure to large amounts of data.
Deep learning belongs to this latter category; a more advanced branch of machine learning that uses neural networks to learn complex relationships directly from data.
A neural network is a learning system inspired by how the human brain processes information. It consists of layers of interconnected units (often called neurons) that pass information forward, gradually learning relationships within the data. Each layer refines the understanding slightly, allowing the system to recognise increasingly complex patterns.
This layered structure is what makes deep learning “deep” i.e multiple layers working together to extract meaning from inputs like text, images, or audio.
You can think of it this way:
Machine Learning teaches systems to recognise patterns based on examples.
Neural Networks are one way of building those learning systems using interconnected layers.
Deep Learning refers to neural networks with many layers capable of handling more complex tasks.
But beyond how complex (or not) the learning system is, another important factor is how it learns.
This is because different learning approaches shape how AI systems interpret data, what problems they can solve, and how much guidance they need during training.
This list isn’t exhaustive, but here are three common learning approaches you’ll hear about:
1.Supervised Learning (Learning From Labeled Examples)
Supervised learning is one of the most common forms of machine learning.
In this approach, the model learns from examples where both the input and the correct output are already known. Essentially, the system is trained using labeled data i.e datasets where humans (or prior systems) have already defined what the correct answer should be.
For example:
Emails labeled as “spam” or “not spam”
Transactions labeled as “fraudulent” or “legitimate”
Customer support tickets categorised by topic
The model learns patterns that connect inputs to outcomes and then uses those patterns to make predictions on new data.
Product implications:
This approach requires high-quality labeled datasets, which can be expensive or time-consuming to create.
Performance depends heavily on the accuracy of labels.
Works well for prediction, classification, and decision-support systems.
Many fintech applications such as fraud detection, credit scoring, and risk prediction rely heavily on supervised learning.
2.Unsupervised Learning( Finding Patterns Without Labels)
Unsupervised learning works differently.
Instead of learning from predefined answers, the model explores data to identify hidden patterns, groupings, or relationships on its own.
There are no labeled outcomes guiding the process, the system discovers structure within the data.
Examples include:
Identifying unusual transaction patterns
Detecting anomalies or outliers
Discovering emerging trends within large datasets
From a product perspective, unsupervised learning is often used for exploration and discovery rather than direct prediction.
Product implications:
This approach is Useful when labeled data doesn’t exist.
It helps uncover insights teams may not already be aware of.
Results can require interpretation because the system identifies patterns, but humans still define meaning.
3. Reinforcement Learning (Learning Through Trial and Feedback)
Reinforcement learning takes a different approach.
Instead of learning from labeled examples, the system learns through interaction with an environment. It makes decisions, receives feedback in the form of rewards or penalties, and gradually improves its behaviour over time.
Think of it as learning through experimentation.
Examples include:
Recommendation systems optimising what content to show
Game-playing AI improving through repeated attempts
Autonomous systems learning optimal strategies
Product implications:
This requires careful definition of reward signals, what the system is optimising for matters deeply.
Poorly designed incentives can lead to unintended behaviour.
Works well in environments where continuous feedback is available.
Core building blocks for AI

Before we go further into models and capabilities, it helps to understand the fundamental pieces that every AI system relies on
1. Data
AI systems learn from data.
Unlike traditional software, where rules are explicitly programmed, AI relies on examples, patterns, and historical information to learn how to produce outputs.
The quality, structure, and relevance of this data directly influence the outcome. Simply put, if garbage goes in, garbage will come right out.
This means:
Bad data leads to bad predictions.
Biased data creates biased results.
Incomplete data creates unreliable behaviour.
For PMs, data is now an essential component. Before using /suggesting ai you must ask
What data do we include/exclude
What is the quality of data we have?
How often is it updated or are even collecting it?
The answers to these questions are key to shaping the intelligence of the system.
2. A Model
At the heart of every AI system is the model, the component that learns from data and turns patterns into predictions or outputs.
The way it works is that It doesn’t guarantee a single correct answer. Instead, it evaluates probabilities and generates the response it believes is most likely based on what it has learned.
This is why AI doesn’t always give the exact same response every time. It’s not selecting from a fixed script, it’s estimating what response is most likely based on what it has learned.
The type of model used depends on the problem being solved and the product context. Factors like the use case, data availability, cost, performance requirements, speed, and reliability all influence which approach makes the most sense.
3. Training
AI systems need a learning phase called training.
During training:
Data is introduced to the model as examples
The system makes predictions and compares them against expected outcomes
Errors are measured, and adjustments are made repeatedly
Over time, these adjustments shape how the model behaves, embedding patterns into the system’s decision-making process.
Training ultimately determines what the AI knows and how well it performs. If the training data is limited, biased, or misaligned with real-world conditions, the model’s performance will suffer, regardless of how advanced the underlying technology is.
4. Compute Power
AI doesn’t just need data and models, it also requires significant computing power to process and learn from information effectively. Training modern AI systems involves running billions of calculations, which is why specialised hardware is often used.
Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are examples of powerful chips designed to handle large volumes of parallel computations, making them particularly well suited for training complex AI models. What once took months of processing time a decade ago can now be completed in hours or days, and this rapid acceleration in compute power is a major reason modern AI capabilities have advanced so quickly.
It is noteworthy that Compute power affects cost, speed, scalability, and feasibility. Understanding this helps product managers make more realistic decisions about timelines, infrastructure requirements, and the trade-offs between model complexity and performance.
5. Inputs
AI doesn’t operate in isolation. It needs something to learn from or respond to.
Inputs are the information given to the system, and they can take many forms: Text prompts, Images, Transactions, User behaviour signals and Structured datasets
The structure and clarity of inputs influence the quality of outputs.
This is why, when building AI products, things like prompt design, data formatting, and even how users interact with the interface become core parts of the product design.
6. Outputs
Outputs are the results an AI system produces, whether that’s generated text, predictions, classifications, or recommendations.
Unlike traditional software where outcomes are fixed and predictable, AI outputs can vary depending on context, inputs, and learned patterns. This means product teams must design with flexibility in mind rather than assuming a single consistent response.
From a product perspective, this introduces new considerations:
Designing experiences that can handle imperfect or unexpected responses
Creating fallback flows when results don’t meet quality thresholds
Setting user expectations around variability and confidence
Building guardrails that maintain trust while allowing useful flexibility
Ultimately, AI outputs are not just technical results; they become part of the user experience, which means how they are presented, validated, and supported is just as important as how they are generated.
7. Feedback Loops
AI systems don’t just learn once, they improve through feedback.
Feedback helps the system understand what is working, what isn’t, and how it should adjust over time. This feedback can come from different sources, such as:
User corrections or interactions
Performance evaluations using new datasets
Continuous retraining with updated information
Without feedback loops, AI systems will slowly lose efficiency and relevance.
Types of AI
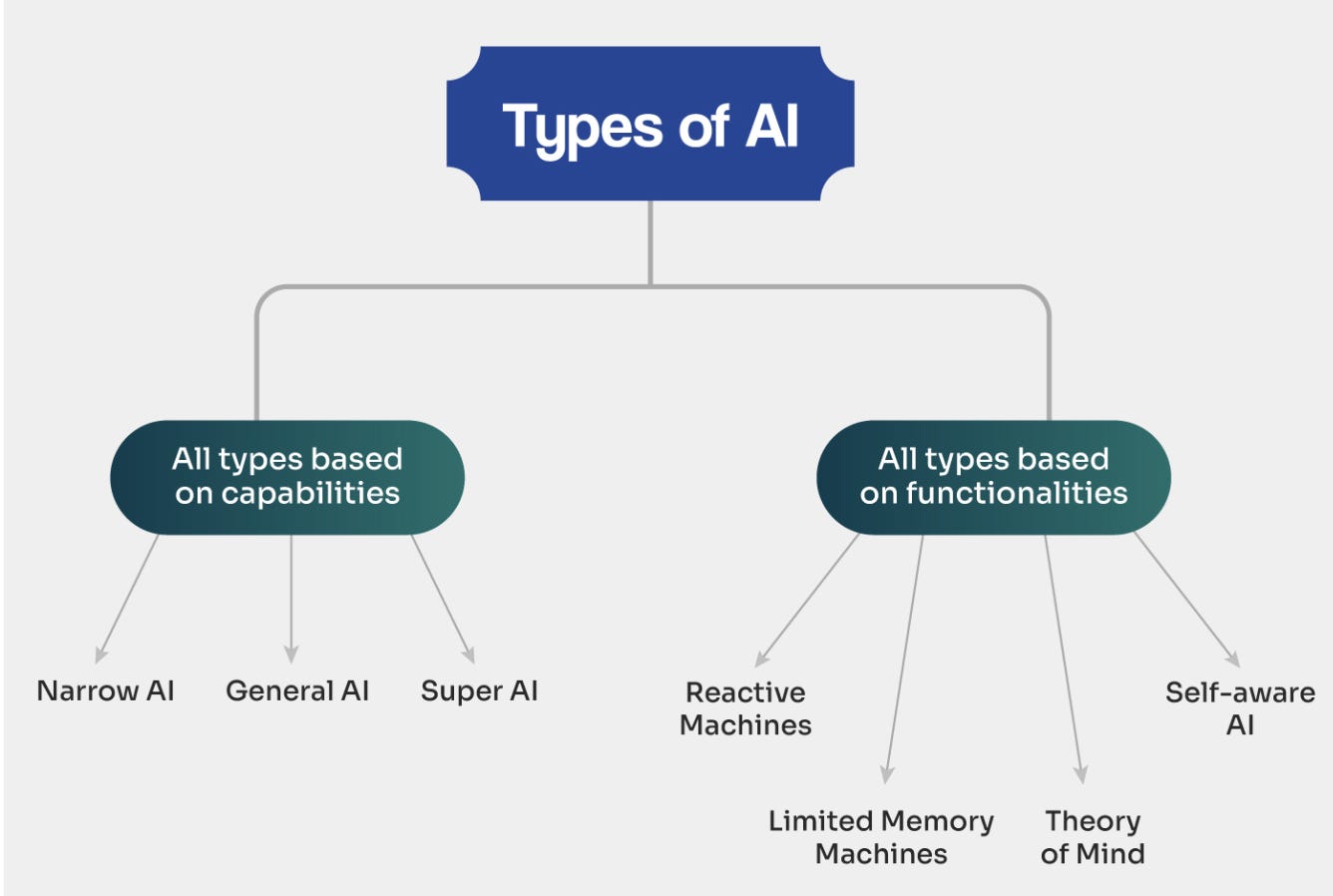
AI can be categorised in different ways depending on what you want to understand. Two common ways are:
based on capabilities (how advanced the intelligence is)
based on functional behaviour (how the system operates)
Types of AI Based on Capabilities
Narrow AI (Weak AI)
Narrow AI refers to systems designed to perform specific tasks within a defined scope. They are highly effective at one function but cannot generalise beyond what they were trained to do. Most real-world AI products today fall into this category.Examples include: recommendation engines (Netflix or Amazon), fraud detection systems, chatbots, facial recognition tools etc
General AI (Artificial General Intelligence — AGI)
General AI describes systems that would be capable of performing any intellectual task a human can do. Unlike narrow AI, AGI would transfer knowledge across different domains and learn independently. This level of AI is still theoretical and does not currently exist in production.Super AI (Artificial Superintelligence)
Super AI refers to a future concept where AI surpasses human intelligence across all areas; reasoning, creativity, decision-making, and learning speed. This is largely discussed in research and ethics conversations rather than practical product development today.
Types of AI Based on Functionalities
Reactive Machines
Reactive AI systems respond only to current inputs and do not store memories or learn from past experiences. They follow learned patterns but cannot adapt over time based on interaction history.
For example, Spam filters based purely on predefined rules rather than learning from user correctionsLimited Memory Machines
Limited memory AI systems use historical data to make decisions or predictions. Most modern AI applications fall into this category because they rely on past examples or training data.
Examples: recommendation systems, credit risk models, Fraud detection models analysing past transaction patterns, personalised content feeds.Theory of Mind AI
Theory of Mind AI refers to systems that would understand human emotions, intentions, or social context. This level of AI is still under research and has not been fully achieved.Self-Aware AI
Self-aware AI represents a theoretical level where systems possess consciousness or awareness of themselves. This remains a conceptual idea rather than something currently used in products.
Quick check-in
I do hope I haven’t lost you yet.

So far, We’ve covered quite a bit; from how AI learns to the building blocks behind it as well as the different types.
This next section is where things start to come together (if it hasn’t already)
Let’s look at the different types of AI models and what they’re designed to do
Common Types of AI Models
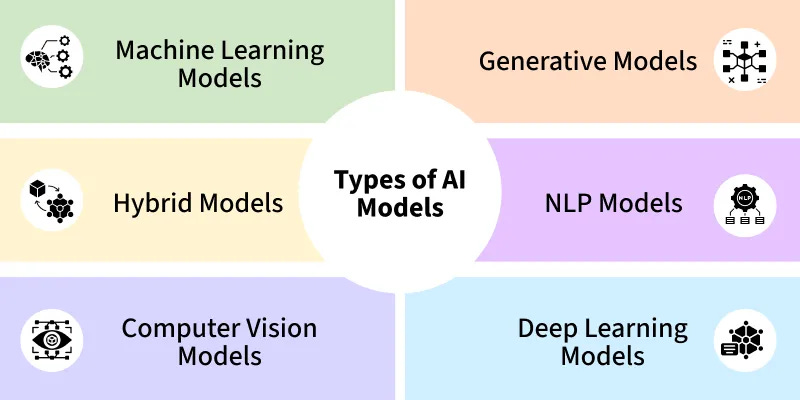
1. Machine Learning Models
Machine learning models are AI systems designed to identify patterns in data and make predictions or decisions based on those patterns.
Earlier in this guide, we talked about machine learning as the overall approach; the idea that AI learns from data instead of following fixed rules.
Here, when we talk about machine learning models, we’re referring to specific systems built using that approach.
These systems typically focus on structured problems where clear patterns exist in historical data.
Common use cases include; Fraud detection, Credit scoring, Demand forecasting, Customer churn prediction etc
If your product needs to predict, classify, or score something based on past data, you’re likely dealing with a machine learning model.
2. Generative Models
Generative models are AI systems designed to create new content rather than simply analyse existing data.
While traditional machine learning systems focus on prediction or classification, generative models learn patterns from large datasets and use those patterns to produce entirely new outputs.
These outputs can include:Text,Images, Audio or music, Video or Code
Examples of generative models include:
Large language models (LLMs) that generate written responses or summaries
Image generation tools that create visuals from prompts
AI coding assistants that generate software snippets
Voice generation or synthetic media systems
For product managers, generative models introduce a different design mindset. Outputs are probabilistic and creative, which means results can vary and require thoughtful guardrails, evaluation, and user experience design.
3. Hybrid Models
Hybrid models combine multiple AI approaches within a single system.
For example:
A rules-based system + machine learning
A classification model + a generative model
Human-in-the-loop workflows with AI assistance
Most production AI systems today are hybrid by design.
Common use cases: Loan underwriting systems, Fraud detection with manual review, AI copilots with guardrails etc.
4. Natural Language Processing (NLP) Models
Natural Language Processing (NLP) models are AI systems designed to understand, interpret, and generate human language.
These models work with text or speech, allowing AI to read, write, summarise, translate, or respond in ways that feel natural to humans.
Earlier in this guide, we discussed deep learning and generative models. NLP models are often built using deep learning techniques, but what makes them distinct is their focus on language-based tasks.
Instead of analysing numerical patterns or images, NLP models specialise in working with words, sentences, and context.
Common use cases: Chatbots and conversational assistants, Text summarisation tools, Translation systems, Sentiment analysis (detecting positive or negative tone), Email or message autocomplete etc.
5. Deep Learning Models
Deep learning models are advanced AI systems designed to learn complex patterns from large amounts of data using layered neural networks.
Earlier in this guide, we described deep learning as a branch of machine learning that uses neural networks with multiple layers to automatically learn patterns from raw inputs like text, images, or audio.
Here, when we talk about deep learning models, we’re referring to specific AI systems built using that approach.
Unlike traditional machine learning systems that often rely on structured data and human-defined inputs, deep learning models can learn directly from more complex or unstructured information.
Examples include: Speech recognition systems, Image classification and object detection, Large language models (LLMs) used in conversational AI, Facial recognition systems and Video analysis tools
Deep learning models are particularly powerful because they can uncover subtle relationships in data that may be difficult to define manually.
6. Computer Vision Models
Computer vision models are AI systems designed to interpret and understand visual information such as images, videos, or live camera feeds.
Just as NLP models focus on language, computer vision models focus on visual perception, enabling machines to “see” and analyse visual content.
These systems learn to recognise patterns in pixels, allowing them to identify objects, detect movement, or understand scenes.
Common examples include:
Facial recognition systems
Image classification (identifying objects in photos)
Self-driving car vision systems that detect roads, pedestrians, or obstacles
Medical imaging analysis (e.g., detecting abnormalities in scans)
Visual search features that allow users to search using images
Earlier, we discussed deep learning models. Many modern computer vision systems rely heavily on deep learning because layered neural networks are particularly effective at learning complex visual patterns.
Key AI terminologies worth knowing

Understanding AI isn’t just about knowing what different systems do, it’s also about understanding the language used to describe them.
1. Training vs Inference
Training is the phase where an AI model learns by analysing data and adjusting itself to recognise patterns.
Inference is the phase where the trained model is used to generate predictions or outputs in real-world scenarios. In simple terms, training is learning, while inference is applying what has been learned. For PMs, inference directly impacts user experience because it affects speed, cost, and reliability.
2. Fine-Tuning
Fine-tuning refers to adapting an already trained model to perform better on a specific task or domain by training it further on targeted data. Instead of building a model from scratch, teams refine an existing one to improve accuracy or relevance.
For example, a general language model might be fine-tuned to understand financial terminology or legal documents.
3. Tokens and Context Window
Tokens are small pieces of text that AI language models process instead of full sentences or paragraphs. A context window refers to how much information the model can consider at once when generating a response.
Larger context windows allow the AI to remember more of the conversation or analyse longer documents, which directly affects performance in tasks like summarisation or dialogue.
4. Hallucinations
Hallucinations occur when an AI system generates responses that sound convincing but are incorrect or fabricated. This happens because generative models predict likely patterns rather than verify factual accuracy.
For product managers, hallucinations highlight the importance of guardrails, validation mechanisms, and user experience design that sets appropriate expectations.
5. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation combines generative AI with external data sources. Instead of relying only on what the model learned during training, it retrieves relevant information from databases or documents and uses that context to generate more accurate responses. This approach helps reduce hallucinations and makes AI outputs more grounded in real data.
6. Large Reasoning Models (LRMs)
Large reasoning models are advanced AI systems designed to handle complex multi-step reasoning tasks rather than just generating responses quickly. They focus on structured thinking, problem-solving, and logical progression. These models are often used for tasks requiring deeper analysis, planning, or technical reasoning.
7. MoE (Mixture of Experts)
Mixture of Experts is an AI architecture where multiple specialised models (experts) handle different parts of a task. Instead of one large model doing everything, the system routes inputs to the most relevant expert, improving efficiency and performance. This approach helps scale AI systems while managing computational costs.
8. AI Agents
AI agents are systems designed to take actions toward a goal rather than simply responding to single prompts. They can plan tasks, make decisions, use tools, and execute multi-step workflows autonomously. Agentic systems represent a shift from AI as a passive responder to AI as an active participant in completing tasks.
9. Large Language Model (LLM)
A Large Language Model (LLM) is a type of AI system trained on massive amounts of text data to understand and generate human language.
LLMs power many modern AI tools, including conversational assistants, text summarisation tools, and coding assistants.
They are typically built using deep learning techniques and specialise in tasks involving language, reasoning, or text generation.
10. Red Teaming
Red teaming is the process of intentionally testing an AI system to identify weaknesses, risks, or unintended behaviours.
Instead of evaluating only whether the system works as expected, red teaming focuses on discovering how the system might fail; including security vulnerabilities, harmful outputs, bias, or ways users could misuse or manipulate the AI.

If this feels like a lot, that’s because it is.
AI introduces new concepts, new ways of thinking, and new challenges for how we build products. But you don’t need to master everything at once. The goal is to understand the fundamentals first.
Think of this as your starting point; a foundation to help you ask better questions, navigate conversations, and make more informed choices as AI becomes increasingly embedded in the products we build.
Throughout this month, we’ll continue breaking AI down into practical, product-focused insights. One concept at a time.
Until next week,

"Knowing how to think with AI" is doing a lot of work in that sentence — the piece explains what supervised/unsupervised/reinforcement learning are, but vocabulary and thinking are different skills. The harder problem for PMs isn't knowing what LLMs are, it's knowing when a given product problem is actually an AI problem versus a data problem versus a process problem with an AI-shaped hammer nearby. The 95% enterprise pilot failure rate (MIT's NANDA initiative, 150 interviews) suggests most PMs who can describe ML approaches still can't distinguish between "this needs a model" and "this needs clean labels and a simple classifier." What would a practical decision framework for that distinction look like — is there a set of questions PMs should ask before reaching for any ML approach at all?
"Knowing how to think with AI" is doing a lot of work in that sentence — the piece explains what supervised/unsupervised/reinforcement learning are, but vocabulary and thinking are different skills. The harder problem for PMs isn't knowing what LLMs are, it's knowing when a given product problem is actually an AI problem versus a data problem versus a process problem with an AI-shaped hammer nearby. The 95% enterprise pilot failure rate (MIT's NANDA initiative, 150 interviews) suggests most PMs who can describe ML approaches still can't distinguish between "this needs a model" and "this needs clean labels and a simple classifier." What would a practical decision framework for that distinction look like — is there a set of questions PMs should ask before reaching for any ML approach at all?